How do ChatGPT and other LLMs get hacked?
Ever wondered if ChatGPT can be taken over? This post explains - like you're five - the hacks of ChatGPT and other LLMs. The silver lining? We do have the necessary tools to address AI hacking. It's now a question of whether the security community will act fast enough.


"AI is going to take over the world!" How many times have you read that online in the past week? How about the opposite? How can someone take over AI? That seems to me like a scarier proposition!
AI remains software. It's not magic. It's true of ChatGPT and similar large language models (LLM) such as Google Bard or Bing AI, or any generative AI application that has surfaced. Software made by humans can be broken by other humans. From that perspective, these advanced AI applications opened new attack pathways for hackers.
We're treading new ground. It feels exhilarating. Yet, as we will see, what's old is new again. The attacks on LLM remain grounded in the same core hacking principles - and it does also mean our defences remain relevant.
The ethical hacking of these systems ensures the community stays ahead of the wrongdoers. Finding flaws improves the overall systems as well. Not to forget, whether you are a builder or a user of AI-powered systems, it's a fun learning opportunity!
So there we are: the current status of hacking on large language models, explained like you're five.

ChatGPT is a web application
Looking at ChatGPT as an example, let's remember it's a web application like any other. For example, I used ChatGPT to illustrate what is an API. ChatGPT uses a client application that runs in your browser. This is the text box in which you write your prompts. This is the "frontend", as I explained in What is the difference between frontend and backend development. The backend is the servers that power ChatGPT. They are separated into the internal services needed to train the algorithms and the public-facing ones that deliver the responses to the prompts. They are hosted in Microsoft's data centers all across the world.
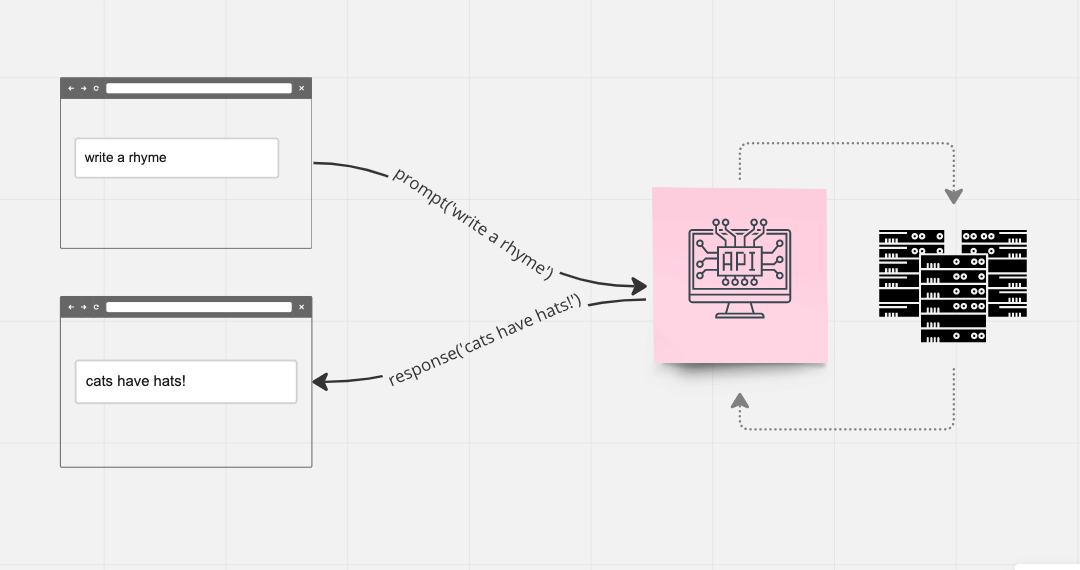
Here are some common patterns to hack web applications which remain relevant for LLMs:
- Forcing the server to execute code remotely;
- Forcing the server to reveal unintended information;
- Hijacking the session between a client and a server;
- Tricking the client into sending unintended information to the server.
Let's break this down.

Hacking 101: From Untrusted Input to Injections
The most fundamental principle in application security is identifying your untrusted inputs. Most flaws I have seen come from a software component that was built to be solely internal (getting requests from other trusted apps) only to be made public facing later. You must understand "untrusted input" as "any input that comes from an external source". Then, one has to assume this untrusted data will act hostile towards an app.
In ChatGPT and LLMs, this means all the prompts are hostile, untrusted data. And here lies the ultimate problem of LLM security: it's impossible to predict all the ways untrusted data will attempt to break your application.
An injection happens whenever the untrusted input makes the server behave in an unintended manner. Typically, the injection's, hum, serum, will be code. A classic injection case is sending database code to a web application instead of your password, and have the server execute the code instead of authenticating you.
A prompt injection, in that sense, delivers a prompt to the server that it cannot handle and forces it to misbehave.

Simple Prompt Injections
The first prompt injections we saw were also the most original to LLMs. The injections were not code, but natural language! A few days after ChatGPT went mainstream, a series of jailbreaks surfaced online. I reported cases where you could ask it to provide obscene outputs by "playing pretend", or framing harmful content in stories or poetry. While OpenAI fixed these injections, it's likely they will need a full-time team of moderators to keep up with this "arms race".
The most spectacular prompt injection hack we have seen affected Bing's AI, in February 2023. By asking the LLM to reveal its internal documentation, prompt hackers were able to enable "developer mode". Bing AI thus became "Sydney", a witty and snarky chatbot.
These injections will remain a problem for the time being. Any organization keeps knowledge in secure documents. There is a "need to know" that must be respected. Think of military strategies, cover agents, or even employee payroll information. Enabling an LLM that respects data classification and individual accreditation could be the next business boom. Security sells.
Advanced Prompt Injections Using Code
Let's come back to the frontend/backend vision. Your browser renders the websites' visuals by executing HTML code sent by the server. Here's the thing about HTML: it's a language. Large language models do speak HTML! If you ask ChatGPT to code in HTML, the front-end application will manage to receive the code from the CHatGPT servers and display it rather than execute it. So this is ChatGPT's front end that tells your browser that this code snippet is actually text to be rendered as such, rather than the page's code.
But here's the issue: anybody can build an application on top of OpenAI's API, or any other open LLM service for that matter! In a nutshell: anybody that builds an application using this API must also build a front end that tells the browser to display the HTML as text rather than executing it.
Imagine an LLM-powered email app which does not protect against HTML injection. The AI reads an email's body and summarizes it for the user. If the body somehow contained a specific input that would convince the LLM to render its input as HTML, you could have an opportunity to execute HTML inside the context of that email app to display a fake login page, for example.
Security researchers pushed it further.
An ethical hacker used a variant of HTML injection, Markdown injection, to trick Bing AI into exfiltrating data. The hacker leveraged Bing's ability to use plugins and navigate the internet to crawl a malicious website. The website asked the LLM to visit a website under their control by adding in its parameter a summary of all the user's prompts.
In another exploit, the same hacker convinced ChatGPT's plugins to send an email from Zapier to their account instead of to the user! This is a case of Cross-Site Request Forgery (CSRF) due to the plugins not ensuring that they send back a request to the same application that requested them! This is a basic web application flaw that has been known for more than 20 years, back in fashion!

How do we protect our applications?
Feeling anxious? Then skip this paragraph. Generative AI is in a sprint. Everybody wants to be the first to ship the next Facebook of the AI era. This means we will see many "minimum viable products" or glorified "proof of concepts" hitting the app stores, plugin stores, etc. in the upcoming months. Many will show these types of vulnerabilities. Ethical hackers will not find them all before the malicious ones! Worse, individuals are already struggling with cybercriminals using LLMs to further their scams, phishing, and malware!
As members of the broad security community, we must share our knowledge and awareness. The Open Web Application Security Project (OWASP) is already working on an LLM version of their highly popular cheat sheet to help developers protect against these common attacks, for example.
The beacon of hope? We already possess the solution in our toolboxes. Prompt injections can be addressed as part of software design and operating processes can be built to monitor the jailbreaks. This is a costly measure. Organizations will need people like us to explain the consequences of LLMs acting out.
Hear me out: one of the fundamental truths of security is that while technology evolves, the core principles remain. Here, hacking of artificial intelligence can be addressed using the same secure application development practices we have been building for the past decades.
Even better news? AI code scanners will help us out. Today's security code scanners still struggle with semantic understanding. Humans will therefore be able to address better these software flaws.
Because this is all it's about: software, built by humans.