What is online search and how does it work?
The most simple, straightforward and fun explanation of how search results appear the way they do on Google, YouTube and Amazon, highlighting why online search engines are important and, well, relevant.


Have you ever wished one page about you went away from Google? I did. Back in 2012, I blogged about local politics in a national newspaper and responded to people in the comments section. Whenever I googled myself, I found my snarky responses. I felt ashamed of getting carried away in futile online arguments.
This is where I started to wonder. How did Google decide which sites belonged on its front page? While I can't do anything to help you bury that page where you look silly from Google, I can at least try to explain to you why it's made it this high.
In this article, I will cover the fundamentals of online search, including but not limited to Google. The topics will include:
- How search engines discover content online
- How do they sort this content
- How the search results are ranked
- How do they manage to give results so fast

It Starts with Crawling
It's not a figure of speech to say Google sends hundreds of thousands of robots every minute all over the internet to visit every website in the world. Crawling content is the action of visiting not only a website but all of its subpages and links. If you want a fancy word, crawling is a recursive operation where the bot reviews a website's arborescence until every element is visited.
The most popular structure for a website is a sitemap. Here is a simplified diagram of the ppfosec.com sitemap
But how does Google find the sitemap? Well, people want their websites to appear in Google, so they simply submit the websites to the Google Search Console! Aside from the search console, when the bots visit a website, they seek the robots.txt file. Here's ppfosec's (read ppfosec's out loud! Yes, I'm that immature). A robots.txt file gives instructions to the crawler and links to the sitemap.
But how does Google find the website in the first place? This is the mind-blowing part. The crawlers do not stop at your sitemap. Every link on any website that links to another website gets crawled. This is why us content creators are so annoying with our prompts to like, share and repost. To exist from Google's perspective, other websites must link to you.
Linking is so important that it also was Google's core ranking strategy, as we'll discuss further below.
What about YouTube and Amazon? The second and third most popular search engines in the world do not share Google's challenges. While Google must crawl the internet as a whole, both YouTube and Amazon crawl the content that is being uploaded on their platform. This is much more convenient, as all they require is to have users upload the content in a format they define, and their crawlers can handle an arborescence that they control.
So now that the crawlers have visited every web page, read all the text, "clicked" all the links, etc. How do they remember what's important about a page? It's a question of indexing.

The Index has all the information at hand
Imagine getting all the text, images and links for all 50 billion websites on the internet and needing to have this information sorted... daunting, isn't it? The data is held in an index, which works pretty much like the index in any encyclopedia.
While I don't know the details of Google's index, we know it contains every word ever seen on the internet, in every language. For example, I built, with ChatGPT, a sample index that lists all terms contained in the vampire corpus and list the films that contain them. For a search engine, the idea would be the same: every website in the world that contains the word "werewolf" would be listed in that index. Query "werewolf" and the list comes back immediately!
| Term | Films |
|---|---|
| blood | Dracula, Interview with the Vampire, Underworld, Let the Right One In, Only Lovers Left Alive, Byzantium, Bram Stoker's Dracula, The Hunger, Thirst, A Girl Walks Home Alone at Night, Cronos, What We Do in the Shadows, Vampires, Shadow of the Vampire, Nosferatu |
| fangs | Dracula, Interview with the Vampire, Underworld, Let the Right One In, Only Lovers Left Alive, Byzantium, Bram Stoker's Dracula, The Hunger, Thirst, A Girl Walks Home Alone at Night, Cronos, What We Do in the Shadows, Vampires, Shadow of the Vampire, Nosferatu |
| vampire | Twilight, Dracula, Interview with the Vampire, Blade, Underworld, Let the Right One In, Only Lovers Left Alive, Byzantium, Bram Stoker's Dracula, The Hunger, Thirst, A Girl Walks Home Alone at Night, Cronos, What We Do in the Shadows, Vampires, Shadow of the Vampire, Nosferatu, Vampire Hunter D: Bloodlust, Vampire's Kiss, Blood for Dracula |
| werewolf | Twilight, Underworld |
| love story | Twilight, Let the Right One In, Only Lovers Left Alive, Byzantium, A Girl Walks Home Alone at Night |
| horror | Dracula, Interview with the Vampire, Blade, Underworld, Let the Right One In, Byzantium, Bram Stoker's Dracula, The Hunger, Thirst, A Girl Walks Home Alone at Night, Cronos, What We Do in the Shadows, Vampires, Shadow of the Vampire, Nosferatu, The Fearless Vampire Killers, Daughters of Darkness, The Addiction, Nadja, Blood and Donuts |
| romance | Twilight, Only Lovers Left Alive, Byzantium |
| silent | Nosferatu |
| parody | Dracula: Dead and Loving It, Vampires Suck |
| animation | Vampire Hunter D: Bloodlust |
| psychological | Thirst, A Girl Walks Home Alone at Night |
| cult | Cronos, Shadow of the Vampire |
What's so fascinating about the indexing process is the various enrichment that can be done on a website. I've already discussed how crawling notes all links to and from a given website. This information is then stored in the index to help calculate a relevancy rating for a website, which can also be stored in the index. The index stores the metadata as well, and may even use machine learning to process the images and videos to extract keywords. More advanced indexing techniques also use artificial intelligence to analyze "semantics". A document may never contain the word "vampires", but if it contains a mention of "blood-sucking Robert Pattinson", it better be in the vampire index!
Both YouTube and Amazon use an index as well. Amazon, for example, adds index entries based on the keywords in the product metadata and description. YouTube uses the metadata as well, which is why creators are incentivized to add special thumbnails, descriptions and timestamps to their videos. The auto caption feature adds rich data to YouTube's index. Whenever you speak about "vampires", your video would get indexed despite the description being about zombies or your stepmother.
So this is how you get answers? Well yes, if it was still 2002...

Ranking is where the AI magic truly happens
The biggest problem with keyword search is that the appearance of a given keyword does not guarantee relevant search results. Compare these two texts:


I know which one I would use if I met a vampire! Yet the first one would invariably come out first in basic keyword searches due to the sheer density of the "vampire" word.
Google was able to solve the keyword problem with its now-famous backlink algorithm. Essentially, instead of relying on keywords, Google search assumed that the most important criterion for a page's relevance is its relative popularity and that popularity was measured by how many other pages linked to it.
These days, every good search relies on machine learning to refine the ranking, by basing it on contextual and behavioural data points. This is how pages get boosted based on their popularity in your location, your individual search history, your device, or your buyer profile. Machine learning is also useful to guess your typos and suggest synonyms based on semantic analysis.
Ranking, therefore, obeys an extremely complex real-time calculation, refined over hundreds of billions of interactions.
In the end, machines struggle with authoritativeness and with content freshness, especially in news. There are literally tens of thousands of people, employed by contractors on behalf of tech giants, that train the algorithms every day to better recognize relevant sources. AI data labelling has become a labour hot topic due to poor working conditions, especially in developing countries.
Now that you've got this humongous index, and these highly complex machine-learning calculations, how can you still get your search answers in milliseconds? Well..

The Search infrastructure
Search engine infrastructures are not public, but there are some fundamentals that can be safely applied to understand how search can be so fast. One of these fundamentals is that many queries repeat themselves over time! Everybody wants cat videos and sandwiches, after all. It's therefore economical for a search engine to "pre-compute" a large number of common queries and offer them as close as possible to end users.
In the image below, I show where search engines can store pre-computed results. "Edge locations" are distributed in major cities and allow very quick retrieval, but low computing capacity. Caches likely contain a much larger number of queries, whereas data centers must be used to compute more complex ones. These data centres are still located all over the world, and they host costly supercomputers.
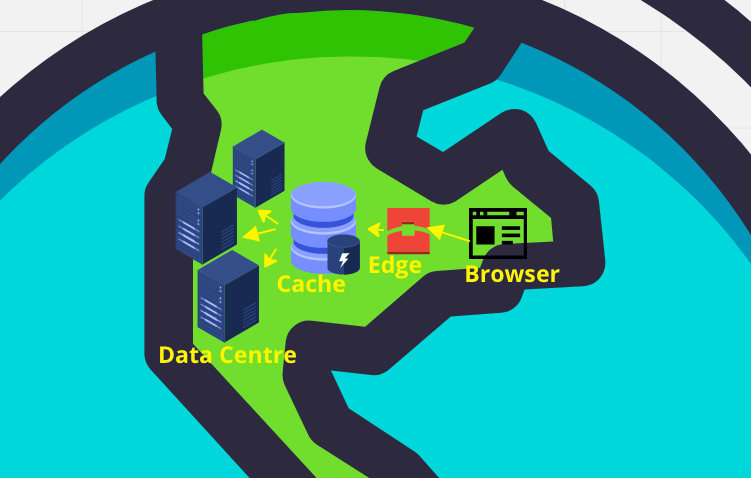
Treat this source with a grain of salt (and not just because the blogger has Bon Jovi hair), but it would seem a typical Google query in 2008 travelled through 700 to 1000 machines in 250 milliseconds. The core idea is that computing still obeys the laws of physics: travelling back and forth from Canada to France in the internet's fibre optics still takes over 100 milliseconds, for example. For fast search, a global computing infrastructure with local data centres is mandatory. Google's infrastructure required so much work that the tech giant was able to offer a part of it for rent as one of the world's leading cloud services providers.
I won't hold you much longer, now go Google yourself.